
The 2025 SONiC Hackathon brought together 31 teams from 12 organizations, guided by 9 judges who evaluated contributions across innovation, scalability, and real-world impact. Among this year’s standout entries, one project delivered a solution that resonated deeply with operators who manage SONiC at scale. The Most Impactful Award went to Hao Cheng and Chengjiu Huang from Alibaba Cloud for their work on “Optimize Output Buffer Memory for Show Commands.”

In large-scale routing environments, even simple operational commands can strain system resources. Hao and Chengjiu took on this real-world challenge with a design that dramatically reduces memory usage during show command execution, preserves system stability, and improves operator experience, all without changing anything at the CLI level. Below, we highlight their winning proposal and how it advances SONiC’s runtime performance.
Team Background & Motivation
The Alibaba Cloud team consists of two engineers: Hao Cheng and Chengjiu Huang, both experienced in operating large-scale routing systems. Their motivation for joining the Hackathon came directly from day-to-day operational pain points.
In FRR-based SONiC deployments, commands like show ip bgp are essential for troubleshooting. But when routing tables contain hundreds of thousands or even millions of routes, these commands can temporarily consume large amounts of memory. This behavior becomes problematic on resource-constrained switching platforms.
Their goal for the Hackathon was clear:
Design a more efficient execution model that ensures stable, predictable memory usage during long-running show commands, without altering behavior or user output.
The Problem
In SONiC operations, vtysh is the primary CLI used to query routing information by communicating with FRR daemons such as bgpd. For large-scale BGP deployments, commands like show ip bgp or show bgp neighbors may need to traverse hundreds of thousands—or even millions—of routes.
During their analysis, the team identified a long-standing issue in how these commands are executed. While traversing the routing table, bgpd continuously writes all output into its internal buffer (obuf) and only begins sending data back to vtysh after the traversal is fully completed. This causes a substantial amount of data to accumulate in memory before any transmission occurs.

Figure 1. Data flow in the original show command pipeline, where output accumulates in obuf.
Although this behavior is manageable for small routing tables, it leads to several challenges in large-scale environments:
- High and unpredictable memory spikes: A single show command may temporarily consume hundreds of megabytes of memory, which is problematic for resource-constrained switching platforms.
- Memory growth tied directly to table size: The larger the BGP table, the higher the peak obuf usage, making resource behavior difficult to predict.
- Potential impact on system stability: Repeated execution can trigger Out-of-Memory (OOM) conditions, causing bgpd to be terminated by the system.
- Limited effectiveness of existing mitigation: FRR includes a threshold-based flush mechanism, but their testing shows it provides only around 10 percent improvement at scale. The core reason is that traversal and buffer writes are significantly faster than IPC transmission, allowing obuf to grow despite frequent flush attempts.
These findings clarified the team’s Hackathon goal: to design a new execution model that maintains stable and predictable memory usage during large show commands, without altering the user-facing behavior. This became the central problem their project set out to solve.

Figure 2. Memory usage of show commands increases linearly with routing table size.
The Hackathon Solution
To address the memory accumulation issue observed when running show commands on large routing tables, the team developed a new execution model based on asynchronous traversal with output flow control. Their goal was not to change the user-visible output, but to make the underlying traversal and transmission process more resource-efficient and predictable during long-running operations.
The core idea is to prevent the traversal speed from outpacing the socket’s ability to send data. When the output buffer (obuf) grows beyond a preset threshold, the traversal is safely paused. The system then attempts to flush the existing data; once the buffer size returns to a safe level, traversal resumes from the exact point where it was suspended. This approach ensures that the growth of obuf is bounded and that the write and send rates remain naturally aligned, eliminating the linear memory increase associated with larger routing tables.
To support this asynchronous model, the team introduced several structural changes to the traversal logic within bgpd. These include a unified state structure to store traversal progress and references, a split between the initialization function and the repeatedly invoked executor, a new CMD_YIELD state to indicate suspension due to buffer limits, and a chunk_used field to track real-time buffer usage. The overall process becomes event-driven, allowing traversal to pause and resume safely while maintaining correct state and reference management.
Compared with FRR’s existing threshold-based flushing mechanism—which attempts a flush once a certain amount of data has been written—the team’s design offers a more targeted solution. Instead of continuously injecting data into obuf regardless of send readiness, the traversal rhythm is now governed by the buffer state itself. Since the socket’s send rate is the real limiting factor, asynchronous traversal ensures that this rate becomes the pacing mechanism, keeping memory usage stable and controlled even under very large routing workloads.
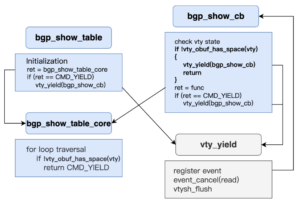
Figure 3. Overview of the asynchronous traversal and output flow-control mechanism.
Impact & Benefits
Their solution delivers substantial improvements to how bgpd handles show commands on large routing tables, all while preserving the familiar user experience. The most notable benefit is that memory usage during query execution is now stably bounded by the configured threshold, rather than growing linearly with the size of the routing table. In their tests, a threshold of 20 chunks resulted in an actual peak usage of around 80 KB—several orders of magnitude lower than the hundreds of megabytes that could previously be consumed in large-scale scenarios.
This predictable resource behavior is particularly valuable for SONiC deployments running on switches or edge platforms where memory is limited. Even in environments with very large BGP tables, a single diagnostic command no longer poses a risk of resource spikes, reducing the chance of OOM events or unexpected performance fluctuations. At the same time, the overall execution time of show commands remains essentially unchanged, since the true bottleneck is the IPC send rate rather than traversal. The asynchronous model keeps data flowing without introducing unnecessary delays.
Beyond memory optimization, the new execution model also improves system stability and responsiveness. Under the previous synchronous approach, bgpd could become occupied for extended periods while generating large outputs, delaying its ability to process other tasks. With asynchronous traversal, the daemon is no longer blocked by long-running commands, allowing it to respond more quickly to other events. For developers and operators, this results in more consistent CLI behavior, clearer resource boundaries, and an improved troubleshooting experience.
More broadly, the approach the team developed can be applied to other commands in SONiC and FRR that require traversing large internal data structures. It provides a general optimization pattern that enhances efficiency without altering functionality, ultimately contributing to a more robust foundation for large-scale network deployments.
Lessons Learned
During the Hackathon, the team gained a clearer understanding of how SONiC and FRR handle show commands internally, particularly the interaction between traversal logic, output buffer management, and IPC transmission. Their testing confirmed that the main challenge was not traversal speed itself, but the mismatch between how quickly data is generated and how quickly it can be sent. This explains why the traditional threshold-based flush mechanism provides limited improvement at scale.
By redesigning the traversal to support suspension and resumption, they observed that maintaining a controlled execution pace is often more important than optimizing a single step in isolation, especially on resource-constrained devices. This insight is broadly applicable to other long-running or large-output commands.
In addition, working through the implementation allowed them to become more familiar with the structure of FRR modules such as bgpd, vty, and the output buffer system. It also gave them a better understanding of how to introduce safe and maintainable changes within the existing framework.
Overall, the Hackathon reinforced the importance of execution-model design in large-scale scenarios and provided valuable experience for future optimization work within SONiC and FRR.
Next Steps
Following the Hackathon implementation, the team’s next step is to extend and validate this mechanism across additional show commands that traverse large internal data structures. They plan to evaluate its general applicability, refine edge-case handling, and ensure consistent behavior under different runtime conditions.
They also intend to collaborate with the SONiC and FRR communities to discuss upstream integration and incorporate feedback to further improve the design. As the model matures, they hope it can serve as a standard approach for handling long-output commands in FRR and SONiC, enabling more predictable and stable resource usage in large-scale deployments.